Learn to code and be in the driver’s seat: Introducing Python for Translation Technology I
Ruben G. Tsui, Adjunct Lecturer 徐嘉煜 兼任講師
Basic computer programming (or perhaps more popularly referred to as coding) skills are not yet in a professional translator or translation researcher’s standard toolbox, but it’s about time they were!
Why Python?
In this text-oriented course we’ll learn how to “speak” the Python language. Python is often described as a learner-friendly computer language. It is the introductory language in many top computer science undergraduate programs in the world (including NTU’s own Computer Science & Information Engineering department). Its strength derives mainly from its simple syntax and a vast and powerful collection of function libraries. It’s also the go-to language for solving real-world problems in machine learning, data science and artificial intelligence these days. In this course we’ll learn how to write Python scripts to process texts in Chinese and English (or in a few dozen other languages, if you’re so inclined) and integrate the results into your research or translation workflow.
You may have heard of the expression if all you have is a hammer, everything looks like a nail. Most of you are no doubt already familiar with spreadsheet apps such as Microsoft Excel or LibreOffice Calc, which are great for many text and general data processing tasks. But if Excel is the only item (the proverbial “hammer”) in your data-processing toolbox, then you’ll have to treat every task associated with text manipulation as a nail! In this course, Python won’t simply become another tool in your toolbox; it’ll in fact help you create a whole new set of tools! Even better, Python doesn’t replace your favorite spreadsheet program (unless that’s what you want to do) but works with and enhance it! One task we’ll do in class is to write a Python script to match entries in the Dictionary of Chinese Idioms (成語典), which are available as an Excel file, against a bilingual corpus to find out how certain idioms are translated into English.
Other coding and data skills
Learning the basics of Python is not the only focus of this course. You’ll also learn how to work with very large text files, those you normally won’t be able to handle with MS Word (another hammer?). An example is the English-Chinese subcorpus of the United Nations Parallel Corpus, which contains 15.8 million sentence pairs (Good luck in opening that file in Word!). You’ll learn the syntax of the powerful Regular Expression language to search for complex patterns in your texts, both programmatically (i.e., with Python code) and with a programmer’s text editor. This is also where the powerful UNIX/Linux/macOS command-line tools (vs. Graphical UI-based apps) come in.
You’ll also learn how to convert between traditional and simplified Chinese texts, how to segment a Chinese sentence into “words” 詞 (as opposed to simply “characters” 字) and learn what UTF-8 means, as well as how to interpret symbols likes zh-TW, en-CA, and ko-KR and what each symbol’s constituent parts are called and represent. Another skill that’s important to translators who wish to create their own translation corpora is automated web scraping, which is the process of downloading and extracting useful data from a website. You’ll learn how to systematically scrape a Chinese-English bilingual news website and create a translation memory (TM) out of the downloaded articles. In the process of analyzing (“parsing”) the web pages, you’ll become familiar with HTML syntax, a bonus if you work on web/software localization projects in the future.
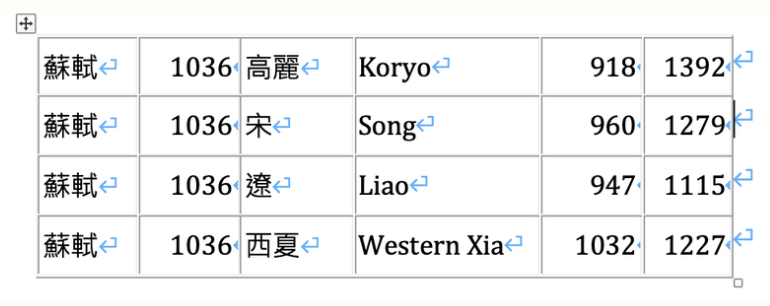
If time permits, we’ll cover the basics of database management systems and the query language known as SQL (Structured Query Language). A great deal of textual resources useful to translators are available in structured database formats. One example is the China Biographical Database, a freely accessible relational database with biographical information about half a million individuals (writers, poets, historical figures, etc.) and a joint project of Harvard University, Peking University and Academic Sinica. A simple SQL query will tell you that the first year of the Jiaqing era in the Qing dynasty (清嘉慶元年) is the year 1796, and a (slightly more complicated SQL) query will yield the fact that the Song-dynasty poet Su Dongpo’s birth year (1036 CE) falls within a period of time when the Song, Koryo, Liao and Western Xia dynasties of East Asia coexisted.
By the end of the course you’ll be surprised how much you can do with only very limited knowledge of Python and a few SQL commands!
What you’ll need to enroll in this course
First of all, you’ll need a lot of motivation and the willingness to learn something entirely new (assuming you haven’t written a single line of computer code). Second, you’ll need to bring a laptop to class. Third, you’ll need to sign up for a free cloud computing account from Amazon SageMaker Studio Lab. (https://studiolab.sagemaker.aws/requestAccount) (Don’t worry, they don’t ask for a credit card number, unlike a few other cloud computing platforms). Google Colaboratory is also acceptable as an alternative platform (although less preferred). If your laptop is powerful enough, I’ll show you how to set up the computing environment right on your own computer.
Finally, if you’d like to be successful in this class, you’ll need to complete most of the coding assignments and present a mini-project at the end of the semester. Remember, you don’t need to be a programmer to be a successful scholar of translation studies or a productive translator, but as the corpus linguist Stefan Th. Gries explains, the ability to use a programming language puts researchers “in the driving seat”. And I sure hope you’ll find yourself in charge of your own automobile in your academic journey (or career as a freelance translator)!
Direct any inquiries regarding this article to the author at RubenTsui@gmail.com.
Reference: Gries, S. T. (2009). What is corpus linguistics? Language and Linguistics Compass, 3, 1–17.