Step out of your comfort zone and … build your own library of translation memories
Ruben G. Tsui 徐嘉煜 (Translation Track, fourth year)
A couple of issues ago I wrote an article in the GPTI Newsletter to show our readers how publicly accessible (and free) cloud computing resources can be used to create a translator’s bilingual concordancer. In this follow-up article, I’d like to demonstrate the creation of translation memory files in TMX (Translation Memory eXchange) format from Microsoft Word and Excel files, using freely available software. These TMX files, once created, can be used in commercial translation software suites/CAT tools or services (SDL Trados Studio and Termsoup come to mind), as well as in open-source translation software (e.g., OmegaT and OpenTM2).
Apart from translation memory (TM) files you might have created in the past from your own translation work, there are also a number of freely accessible bilingual texts that we can obtain from the Web. One of such resources is the American Institute in Taiwan (AIT) website. Specifically, the News & Events section (www.ait.org.tw/news-events/) contains over a thousand bilingual articles, the majority of which are English texts translated into Chinese. I recently wrote a web-scraping script to retrieve all available news articles from the AIT website and converted them into a single Word file. Here’s what a short news article looks like:

Those of us who don’t use commercial TM software may have done most of our translation work in Word or Excel (and kept the data there, forgotten), and if you’ve kept the source and target segments separate (but next to each other) like the above AIT news article, that’s great news. I’ll show you how to turn your two-column table into TMX so that you can build your own library of TM resources for your future translation projects!
The software we’ll be using is called Heartsome TMX Editor, a program that was previously sold commercially but has now been made free of charge by its developers. Windows, macOS and Linux versions are available. Download information is available from the Github page below:
https://github.com/heartsome/tmxeditor8
After the software has been unzipped to your preferred application folder (e.g. C:\apps), navigate to the directory HSTMXEditor_8_0_0_Win_x64_JRE and double-click on the (executable) file Heartsome TMX Editor.exe. Note: It’s always a good idea to virus-scan everything you download from the Internet. Once the program is launched, the initial screen looks something like the following:
Let’s download the AIT news corpus file (ait.sample.docx; about 5.4 MB) from my NTU Space shared folder:
https://www.space.ntu.edu.tw/navigate/s/043CA3F7F7B442C2978D0F8D411EC6ABQQY
From the Heartsome TMX Editor’s menu, select Tools à Convert to TMX …
You’ll be presented with the following dialog box:
Press the first Browse… button and select the Source file (the file downloaded earlier). Then press the second Browse… button to select the folder that will contain the newly created TMX file.
Here the new TMX file will be located in the same folder as the Source file. Also note that if you have an existing TMX (with identical language columns), you can select the Append to a TMX option.
Next, hit the OK button to start the conversion process. Once it’s done, you’ll find the TMX file in the designated folder (ait.sample.tmx; about 10 MB). Now drag and drop this TMX file onto the Heartsome TMX Editor’s blank area. The screen should look something like this:
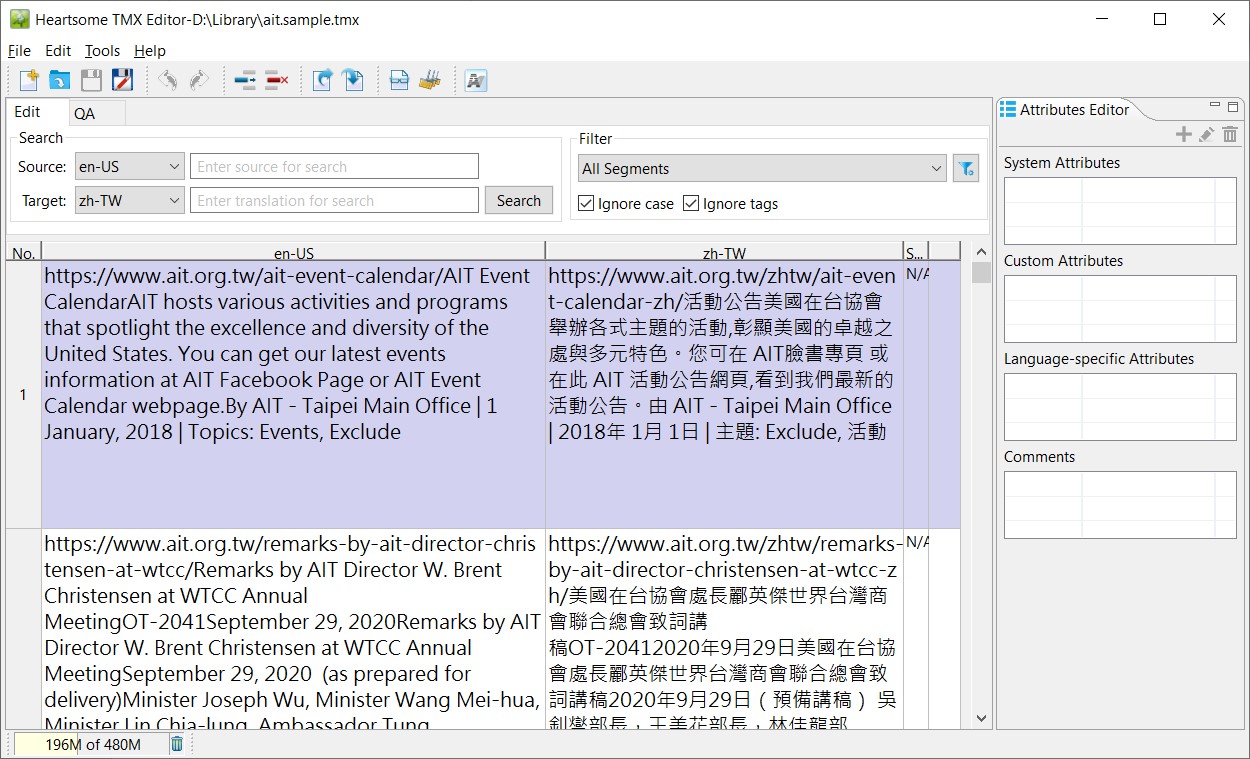
Now, suppose we wish to search the phrase Visa Waiver Program in the English column and try to figure out what its Chinese equivalent is. Simply type the phrase into the Source (‘en-US’) search box and press the Search button:

(Sorry, no regular expression search)
Two segments that contain the search phrase appear below:


Please note that the AIT sample has very large segments, so we need to adjust the column widths in an optimal way in order to better match the source and target sentences. This way it’d be easier to locate the translation equivalent. One other important thing to remember. The table containing your source and target segments (whether in Word or Excel) must have the ISO-639-1 two-letter language codes as the column header, e.g., en for English and zh for Chinese (refer to the AIT Word file above). To distinguish between dialects of the same language, the optional locale can be attached (e.g. en-US vs. en-GB and zh-TW vs. zh-CN vs. zh-HK).
Rescue your brilliant past translation work from oblivion. Starting building your TM library today!
Direct any inquiries regarding this article to the author at RubenTsui@gmail.com.