Setting up your own DIY Concordancer is NOT as difficult as you might think
Ruben G. Tsui 徐嘉煜 (Translation Track, third year)
Arguably the most useful tool in a translator’s toolbox, a bilingual concordancer is essentially a “keyword in context” search engine that displays passages containing a key word or phrase in the source language and also, more importantly, the translation of those passages in the target language. Those of us who use computer-assisted translation (CAT) tools such as SDL Trados Studio or MemoQ on a daily basis are already familiar with the concept of translation memory (TM), and they are also probably skilled at creating their own TMs from various bilingual sources to help with their freelance translation work. In this article I address those of us who don’t have access to TM software (or find such tools not terribly useful) but would like to take advantage of the vast quantity of bilingual resources freely available from the Internet and to build their own bilingual corpora and search engine.
One terrific online resource available to translators, especially those translating articles pertaining to Taiwanese culture from Chinese into English, is the Chinese-English Bilingual Concordancer (華英雙語索引典系統 coct.naer.edu.tw/bc/) provided by the National Academy for Educational Research (NAER; 國家教育研究院). Terms and named entities specific to Taiwan, such as珍珠奶茶 (“pearl milk tea“), 檳榔西施 (“betel nut beauty”) and 雲門舞集 (“Cloud Gate Dance Theater”), can be quickly looked up with confidence. The quality of English translation provided on this platform is generally high, as the underlying corpus is derived from the Taiwan Panorama magazine (台灣光華雜誌), the articles of which are for the most part translated by native speakers of English. Despite its rich and diverse cultural contents, however, the NAER Bilingual Concordancer is unfortunately not updated very frequently. Nor does it contain bilingual texts other than the one stated above, at least as of March 2020.
Enter the world of do-it-yourself bilingual concordancers created with freely available parallel corpora and on free (or low-cost) cloud computing platforms. Jupyter Notebook is an open-source project that has gained wide acceptance in the world of computing. It provides an interactive interface that brings together computer code (in Python, R, and dozens of other computer languages), formatted text and mathematical formulas as well as charts and graphics into a single document known as the notebook.
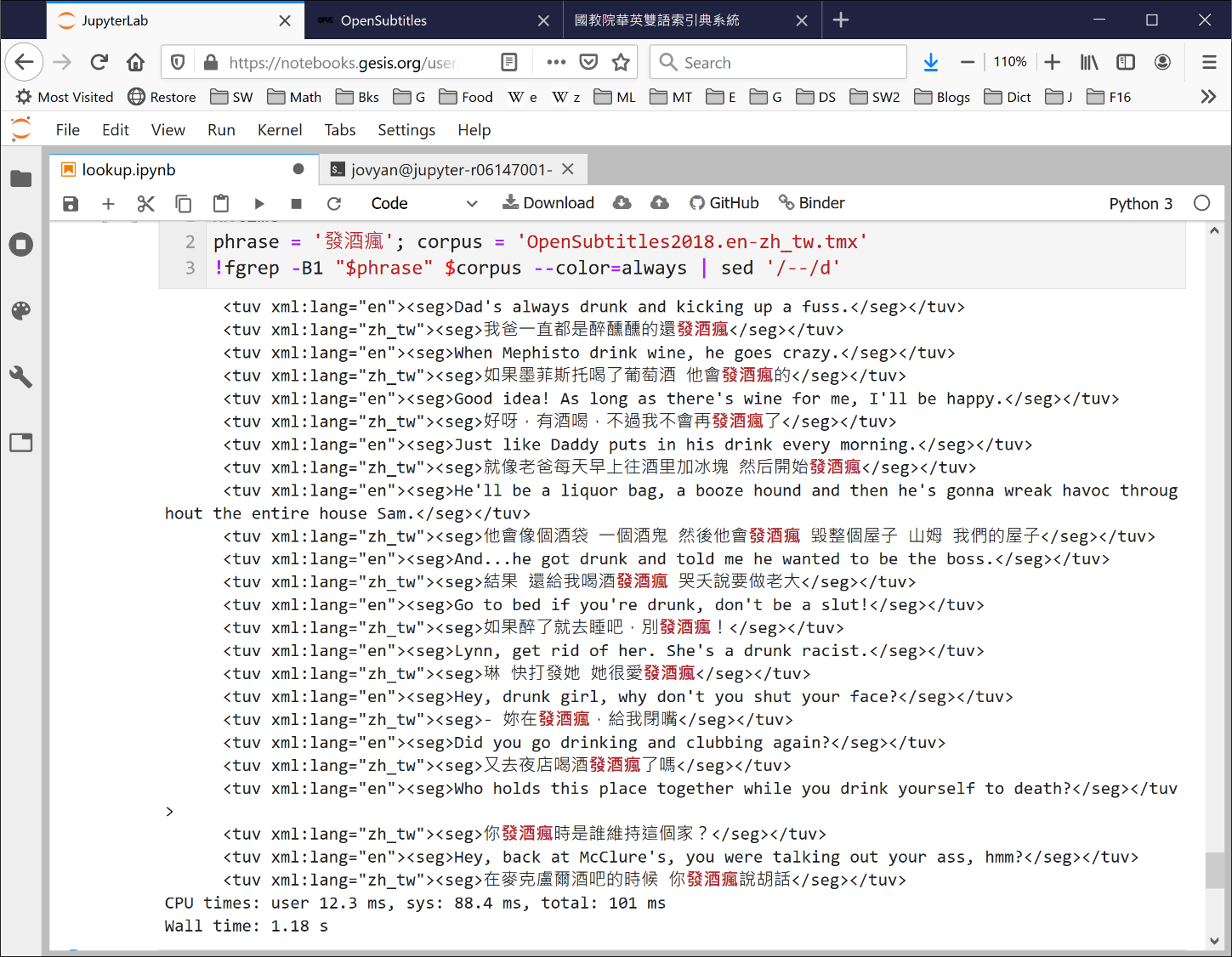
Using one of such notebooks running on a free cloud computing services provider and the OpenSubtitles 2018 corpus (containing 4.3-million pairs of utterances for the language pair en-zh_TW), available from the OPUS open parallel corpus website opus.nlpl.eu/OpenSubtitles-v2018.php, the phrase 發酒瘋and its various possible translation equivalents can be looked up in under a few seconds.
Here’s another scenario. Say you want to figure out the English term for steroids or similar substances (as in doping in sports) and its Chinese equivalent(s), but you
don’t exactly recall specifically whether it’s performance enhancement drug or performance enhancing drug (or some other variant with or without the hyphen). Apart from trying to look it up in Wikipedia, you can use a powerful search-pattern language known as regular expression to find passages that match your “fuzzy” search specification in, say, a corpus consisting of half a million pairs of news article paragraphs you’ve collected from The New York Times English-Chinese bilingual website (https://cn.nytimes.com 紐約時報中文網).
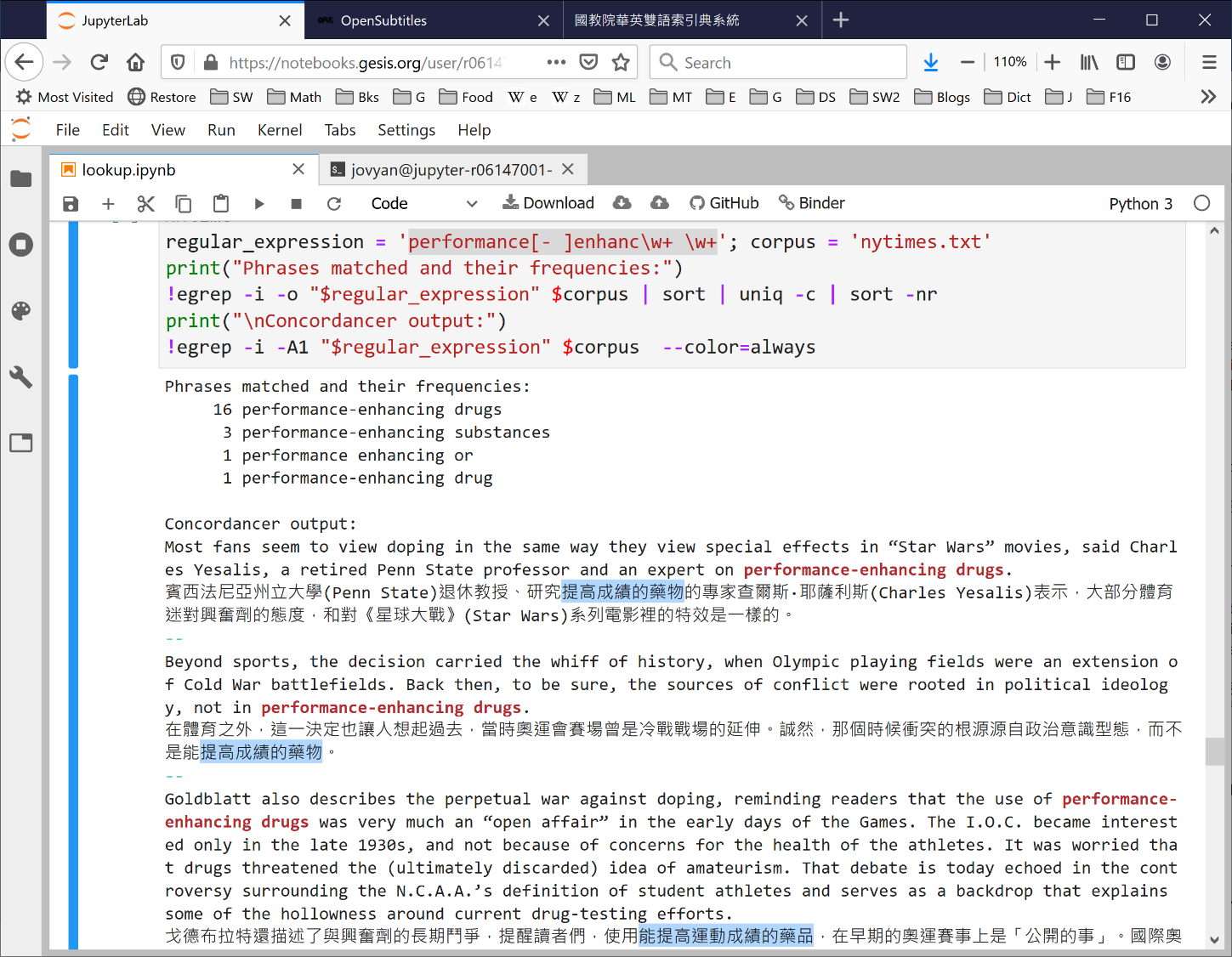
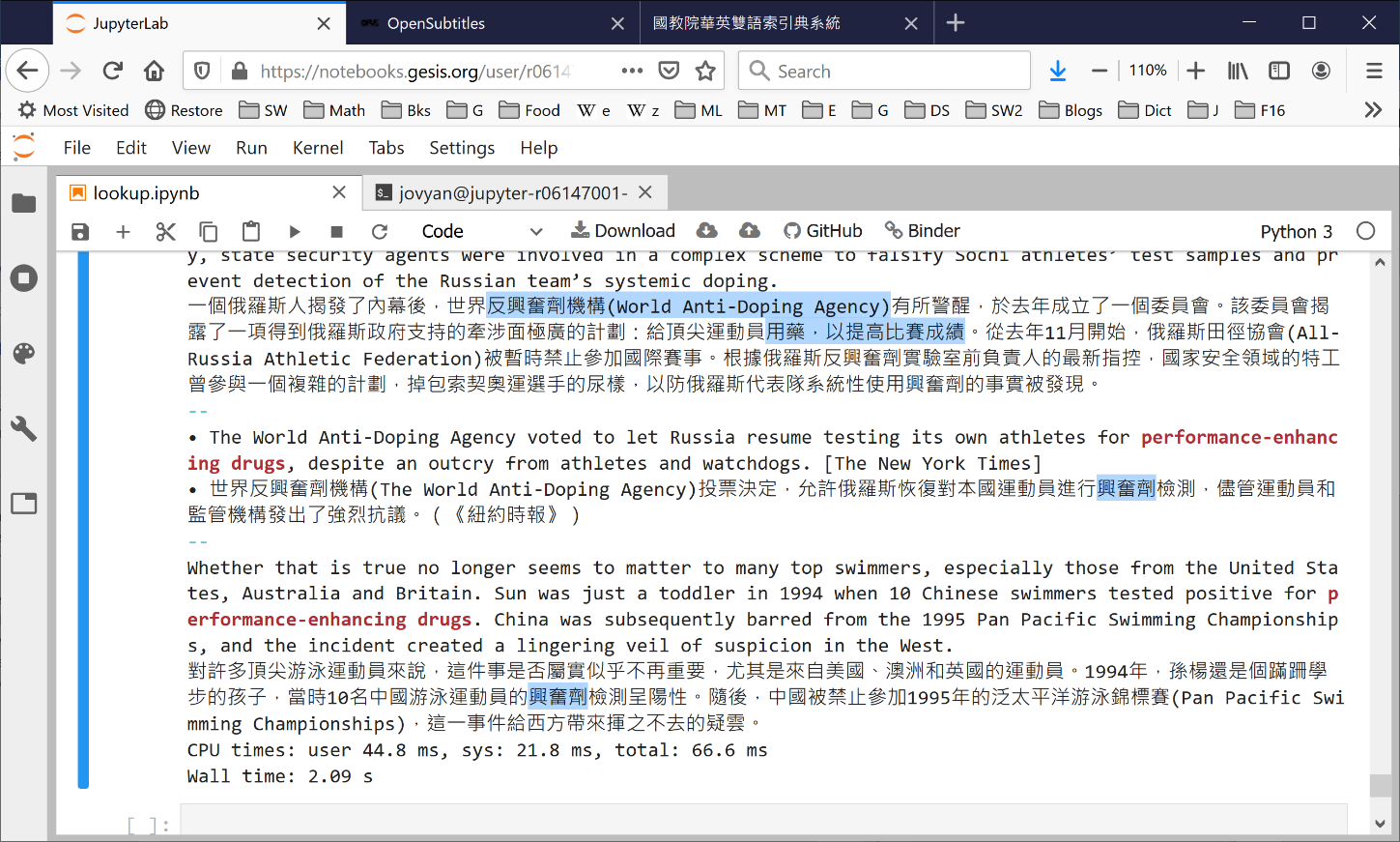
* Note: The relevant Chinese phrases have been highlighted manually and not automatically by the system.
The (somewhat mysterious-looking) regular expression (or regex for short)
performance[- ]enhanc\w+ \w+
searches for the (literal) string performance, followed by either a hyphen or a space character ([- ]), followed by the “prefix” enhanc, followed by one or more letters (\w+), then a space and another sequence of letters (\w+).
The combination enhanc\w+ will match, if such expressions exist in the corpus, enhance, enhances, enhancing, enhanced and enhancement, among others. The last part of the regex (\w+) means “match any word at all”.
If you’re feeling adventurous and would like to get your hands on these tools, head over to one of the following Jupyter Notebook cloud computing websites:
notebooks.gesis.org/binder/v2/gh/ruben-tsui/TranslationTechnology/master?urlpath=lab
(courtesy of GESIS – Leibniz Institute for the Social Sciences)
mybinder.org/v2/gh/ruben-tsui/TranslationTechnology/master?urlpath=lab
(courtesy of the Binder Project)
Double-click on the file search.ipynb in the left panel (showing list of files in the current folder). Then click File | Run All Cells from the menu. Sit back, relax, and see the results for yourself! The first two cells (or blocks of computer code) download large data files over the Internet, so be patient. Change the value of the phrase variable under the subsection Search OpenSubtitles 2018 from 發酒瘋 to something else to explore the OpenSubtitles corpus. By all means experiment with the regex variable under the subsection Search sample New York Times corpus! To execute the code in only one cell, select that cell and hit the Play ▶ button on the toolbar.
Notes:
- Since these cloud computing platforms are provided free-of-charge, please be reminded that they tend to terminate your session after a period of inactivity. Simply revisit the URL(s) provided in this article to re-establish a new session.
- All files created or downloaded on Binder will be lost upon termination of the session. However, while a session is still in progress you can always download a file to your computer by simply right-clicking on the file and selecting Download.
- Please direct any inquiries to the author’s email address at RubenTsui@gmail.com.